

Columns
SEND, FDA, and Industry Movement
Beginning of SEND
Currently, many people are aware of the existence of SEND*1; personally it was about 15 years ago that I first became aware of SEND. At that time, I was working for a company based in Switzerland, and I remember that the computer system used in the research facility had an unfamiliar data transfer tab called SEND in the comments input screen. Of course, at the time SEND was not required in the United States, but FDA had already started to consider implementation of SEND, and IT vendors in the US and Europe had started experimental use. At present, all data submissions to FDA, with a few exceptions, are required to be submitted in a standardized electronic format.
Pharmaceutical companies often use multiple CROs at home and abroad, and have to convert the results from these various data sets into a comprehensive SEND data set. This creates a huge amount of extra work. In addition, even if SEND data can be received directly from the CRO, the applicant's pharmaceutical manufacturer has to certify that the SEND data accurately and completely reflect the original GLP compliant data. This requires additional work on the part of the applicant to ensure that the data have undergone the appropriate quality and QC evaluations.
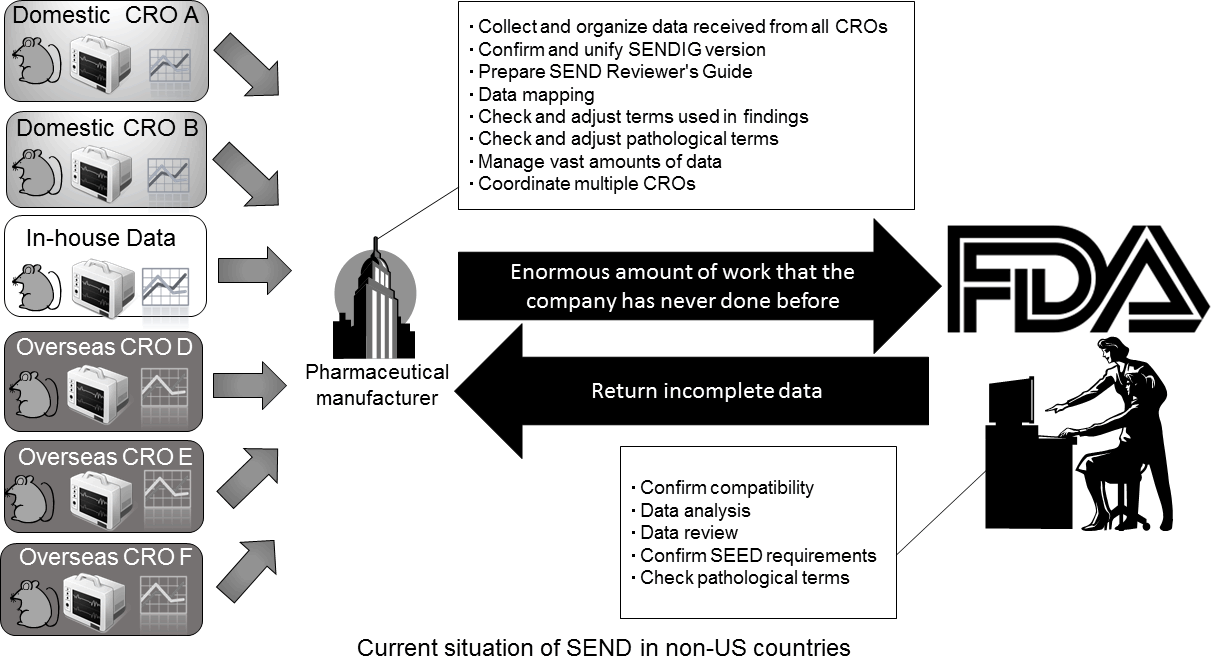
Reproduced with permission of the Japanese Society of Toxicologic Pathology from Anzai et al. "Establishment of the Global SEND Alliance (G-SEND) in Japan and efficient creation of electronic SEND datasets between CROs.", J Toxicol Pathol., 28(2): 57-64, 2015
So why did FDA insist on electronic data submissions, requiring applicants to spend so much time and money, and putting additional pressure on pharmaceutical manufacturers? If you look at their IT five-year plan, the ten-year plan, the "just cause" can be understood. However, I personally think that the truth lies deeper.
Speculative thought about the just cause and drug discovery?
First of all, the just cause is that it takes a lot of time to evaluate application data for new drugs, so shortening this review time benefits applicants, medical professionals, and patients. In fact, I heard from an FDA reviewer that a lot of time was spent on comparing the applied product with the original product. However, having both the past and present data in a uniform electronic format makes it much easier to compare the data and significantly reduces review time. In addition, one of the benefits is that future adverse events can be quickly searched and analyzed. Naturally, comparative analysis with similar drugs could be performed smoothly.
Apart from this just cause, I personally think that there is a true purpose that lies deeper than the FDA-stated aims. That true purpose is AI. SEND's examination was started around the same period of transition from the second AI boom to the third, when Big Data, that is, machine learning (machine learning research) was about to begin. Since then, some of the AI research, such as automated driving, is already beginning to make a major difference in our society. Naturally, bioinformatics represented by data mining is also developing in our field. In the future, AI will be an indispensable tool in drug development as well. But there are big challenges.
If a large amount of past data is to be analyzed by AI for drug development or drug safety and efficacy assessment, those data must be in a standardized format that allows retrieval by machines. Then SEND emerges. FDA has launched electronic data standardization of not only non-clinical but also, of course, of clinical data at the same time. It is probable that this valuable Big Data that will dramatically change drug development over the next 10 or 20 years. The development of AI is also remarkable. It will not be long before AI is able to design innovative drugs with high efficacy and safety based on the big data. On the ground of this prediction, the true spirit of the US can be viewed as maintaining the status as a drug development country with an intellectual property strategy. In other words, it is necessary to be aware that SEND is not merely a standard regulatory system for electronic data conversion, but also has the potential to be greatly involved in drug discovery and safety research in the future.
How pharmaceutical companies corresponding SEND?
In Japan as well as in other countries, pharmaceutical companies and CROs, except for some leading drug companies and CROs, seem to be finally finishing the learning phase of SEND. Presently, organizations such as CDISC*2 and PhUSE*3 function to help educate submitters of SEND data. Although many pharmaceutical companies continue to study SEND while belonging to these organizations, I think that this results in 2 contrasting groups that differ in the ways they approach SEND. This difference can been seen whether the companies regarded SEND as an IT issue and responded with huge capital investments to be able to perform their own data conversions, or regarded it as an application technology issue and depended on outsourcing of their data conversions using RSP*4 for each development product.
The answer is clear: many pharmaceutical companies outsource more than 60%, or sometimes even more than 80%, of the application trials to the CROs, while the GLP compliant studies conducted inside the pharmaceutical companies are limited. Therefore, there are no business benefits to invest in several hundreds of millions of yen and human resources for a few in-house studies, and to create a SEND data set on their own. Also, no matter how much money is spent making a large capital investment, it is the safety department, not the data management department, that eventually makes the application documents for non-clinical studies.
On the other hand, the method of performing SEND conversion is now becoming more standardized, allowing companies to avoid huge capital and human investments. In this case, the cost of the data conversion is covered by the company`s development budget on an individual program basis (generally, 10% to 20% of the study or trial cost is added as the SEND budget). The result is that the company does not have to bear fixed costs (capital investment or human investment) that would continue to be incurred regardless of the level of SEND conversion activity at any given time. Therefore, outsourcing the conversion method becomes much more economical, while still allowing pharmaceutical companies to have expert support. The problem is that there are few proven RSPs and CROs. It seems like many pharmaceutical companies that use this approach have concluded comprehensive contracts with these RSPs or CROs supported by RSPs to provide data conversion at an earlier stage in the non-clinical development program. These pharmaceutical companies have multiple development products ongoing at any given time, and have no time for financial and human investment in SEND. For such busy pharmaceutical companies, it is more important how quickly they can build up a reliable SEND data set. Fortunately, those busy companies tend to be more successful. After all, data conversion in SEND is not the main business for pharmaceutical companies.
The new movement of CROs and the light of hope for pharmaceutical companies
As CROs are required more and more to provide SEND data sets as part of the non-clinical testing they perform, CROs have established G-SEND*5, a non-profit consortium to assist them in responding to requests from pharmaceutical companies. G-SEND selected a CRO to be a SEND data creation base and the base CRO implements data conversion with common tools and processes. Most CROs only perform SEND data creation for entrusted tests (contracted studies and trials), but in G-SEND, the central CRO, as the SEND base, performs SEND data creation for in-house studies and trials of pharmaceutical companies. In addition, it is possible for the member CROs to receive RSP support, such as receiving the latest FDA information, sharing technical information, standardizing the SEND data creation process with G-SEND, and quality improvement. Those advantages eventually benefit pharmaceutical companies in that they can uniform, high-quality SEND data sets with no variability. While CDISC and PhUSE can be called their SEND "teaching" institutions, G-SEND can be said to be a SEND "practice" institution.
Currently, G-SEND consists of 16 companies, centered on Japanese CROs, and other members from six countries: South Korea, Taiwan, Singapore, the US, and Switzerland. Since there are many peers in the same business, strict consortium management is performed and the members can receive full support from RSP. Of course, there are some CROs that continue to handle SEND independently, but there is no doubt that correspondence as a group is superior as a regulatory response business model. Also, in joint research by PhUSE and FDA, a multi-site study involving several CROs has announced a scenario in which a CRO s a SEND data creation base is defined. In any case, the business model in which CROs organize to use G-SEND for standardized data conversion as a group is destined to have a significant impact on their ability to provide compliant error-free SEND data. Also, there is no doubt that this is good news (a light of hope?) for pharmaceutical companies.
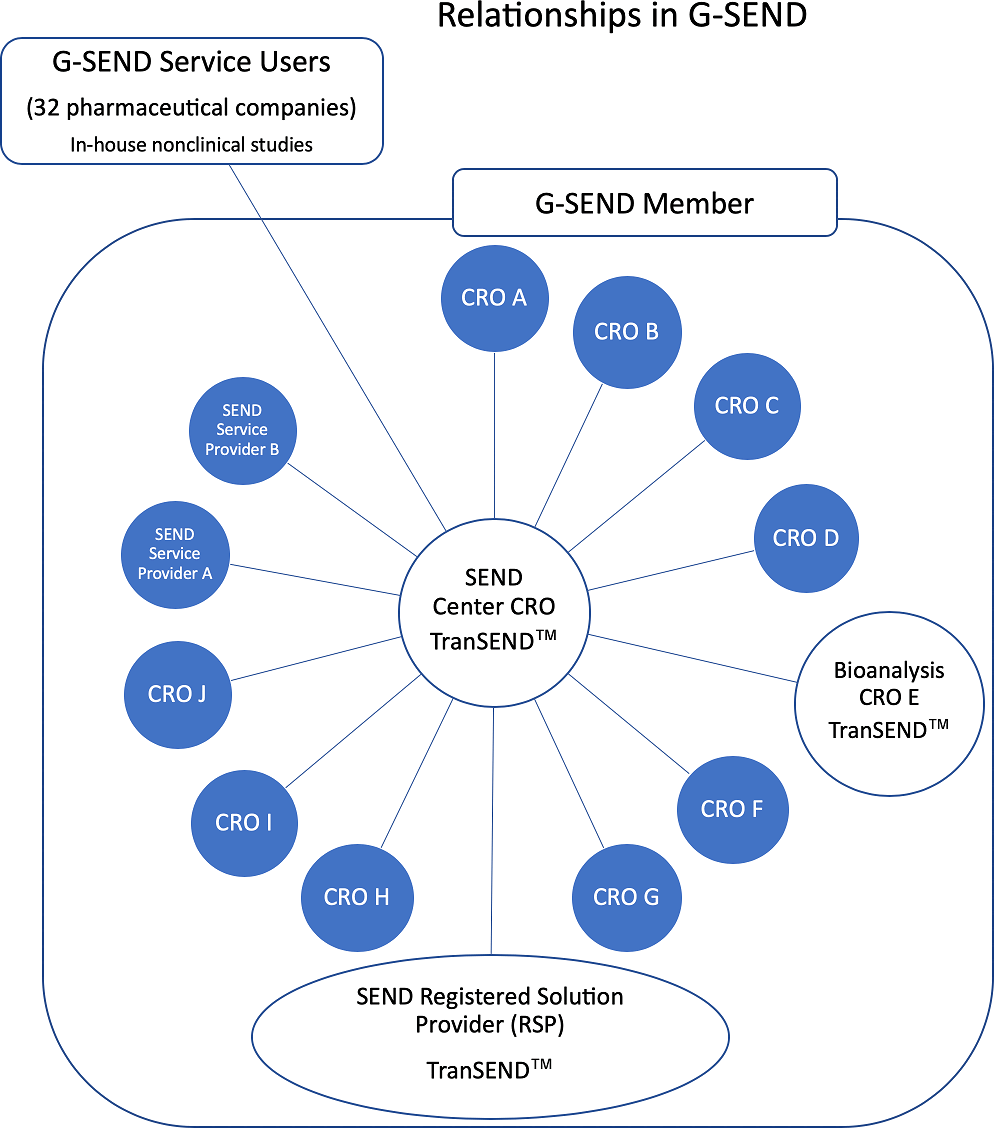 Reproduced with permission of the Japanese Society of Toxicologic Pathology from Anzai et al. "Establishment of the Global SEND Alliance (G-SEND) in Japan and efficient creation of electronic SEND datasets between CROs.", J Toxicol Pathol., 32(2): 119-126, 2019.
Reproduced with permission of the Japanese Society of Toxicologic Pathology from Anzai et al. "Establishment of the Global SEND Alliance (G-SEND) in Japan and efficient creation of electronic SEND datasets between CROs.", J Toxicol Pathol., 32(2): 119-126, 2019.
Pharmaceutical companies focused on technology, performance, and cost when consigning studies and trials to CROs, but now a new selection criterion is added. That is whether the CRO can provide high quality SEND data that can pass FDA review reliably, or the CRO is a member of the G-SEND consortium.
From now on, I will also pay attention to the regulations and movement of electronic data submission in Japan, Europe and Asia, and expect that there will be an opportunity to provide information to you in the future.
June 2019
Takayuki Anzai, PhD., Dr.Med.Sci., MBA
Professor (AP), Showa University, School of Medicine
*1 SEND: Standard for Exchange of Nonclinical Data
*2 CDISC: Clinical Data Interchange Standards Consortium
*3 PhUSE: Pharmaceutical Users Software Exchange
*4 RSP: SEND Registered Solution Provider registered in CDISC5
*5 G-SEND: Global SEND Alliance
Reference
- Establishment of the Global SEND Alliance (G-SEND) in Japan and efficient creation of electronic SEND datasets between CROs. https://www.ncbi.nlm.nih.gov/pubmed/31092979
- Responses to the Standard for Exchange of Nonclinical Data (SEND) in non-US countries. https://www.ncbi.nlm.nih.gov/pubmed/26028814
- Specific pathologist responses for Standard for Exchange of Nonclinical Data (SEND). https://www.ncbi.nlm.nih.gov/pubmed/28798527
![]()